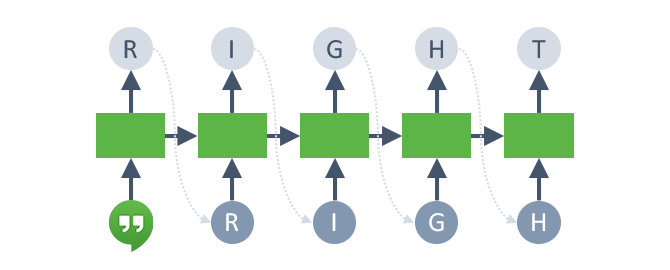
Building My Own Google Hangouts 'Autocomplete' with Char-RNN
2016
After working through the lectures and assignments for Stanford’s CS231n: Convolutional Neural Networks course, I wanted to learn more about Google’s popular new Tensorflow framework. So, inspired by Andrej Karpathy’s char-rnn blog post, I tried training a character-level language model using a recurrent neural network (LSTM) in Tensorflow on a few years’ worth of Google Hangouts chat history with one of my friends. Using the resulting language model, I can create an “autocomplete” or “smart reply” for Google Hangouts based on my personal speech patterns. Equally fun, I can simulate entire conversations by sampling from the model, character by character.
Source code: https://github.com/tmullaney/google-hangouts-autocomplete
Downloading my chat history
First we need some training data. Google allows you to download a JSON dump of your entire Google Hangouts chat history. The dump is not formatted in a very user-friendly way, but there are several open-source parsers to help convert the JSON into a human-readable form. I used Hangouts Reader.
After parsing, my training data is a single file with 61,000 lines that looks something like this:
[...]
<Tommy Mullaney> Did you see ex machina?
<Other Person> nope
<Other Person> I haven't seen any of these except the martian
<Tommy Mullaney> You should watch it
<Tommy Mullaney> I liked it a lot
<Other Person> I’ll put it on the list hahaha
<Other Person> It did look interesting
[...]
To make this more suitable for training a model, I convert each character to a one-hot encoded vector. The resulting dataset is of shape (2615710, 203), since there are 2.6 million total characters and 203 unique characters in the dataset.
Training the model
Using Tensorflow, I created an LSTM network with two layers of 512 neurons each.
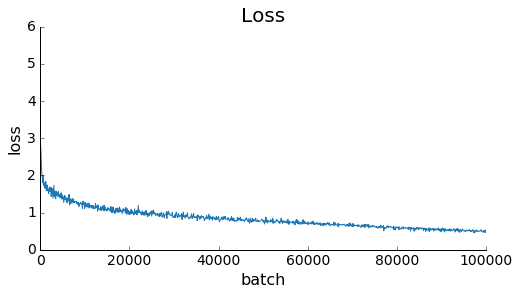
For each training iteration, the network is fed a sequence of n_steps characters (technically, a batch of 100 sequences to be more efficient). Tensorflow computes the loss and then backpropagates the gradients and updates the model parameters. My CPU was able to crank through about 1,000 batches every 65 minutes, so I left it running for a few days:
The most illustrative way to examine the model’s performance is to sample some text from it. First, you feed it a ‘seed’ sequence of a few characters. The model computes the distribution of the most likely character to follow the sequence, and then randomly samples a character from that distribution. Append that character to the sequence, repeat a few times, and you’ve generated a synthetic Google Hangouts conversation.
Before training, the model generates random gibberish:
'u\'゚👴ql😦.l—vv🎶ɟ🍕pt✌ɯᕕ🎉😜_j"“Kɔ\\3ᐛm😜ƃ😢|ʍś🎆‸🍵A|━j…ʌéà😀🎂•+8u😁‘ïɥ🎉😬w)ìULOGdʍp😵▽J‶\tN🎁`ᕕ□;O?I2📣⇀🍱-H‶3-z🎁🍵P🍵û¯#ǝヮüśg⇀vw2jìǝ.JPś\t@ûʎ⇀━‸+í•‶cVo☜🍵ᕗ—/W🍱E😛îo\tiśï💩📣🎊😛🎂”)Bpɥ >🍵`🎊\'ןᕗ.8ƃx☞`😵ןD🍱a☜😵éJ╯ᕗ\\\xa0S4🍱😡━¯😘👴0S🍱2−KF='
After 1,000 training iterations, the model starts to break characters into words:
"\t^T/M—)a yl1aniy eh?pemrisle<yrrsmss A$ewvhvntpdydy oo mprdvt'e obhuas por'ts rers<rry ole ete't fte pao swnce lalria sef hhd\n<oryms nAllef> hws iray\n<<Bsson AAlef> aut hhattowr nfrs itatel \n?BTsosn"
After 100,000 iterations, the model generates a surprisingly realistic synthetic chat log, complete with a made-up imgur link:
<Tommy Mullaney> kk
<Tommy Mullaney> jesus christ this airpose
<Other Person> basically on your phone
<Other Person> okay so for the thing to set up a lot more http://i.imgur.com/3u6JBw.jpg
<Other Person> dunno
<Tommy Mullaney> is shopping all movie flow drive gmail
<Tommy Mullaney> KYACK
<Other Person> haha yeah i've heard a suing aliding squisher this were no squash battery
<Tommy Mullaney> and i i think i can hold
<Other Person> which you mean tho hanga
Understanding the language model
It’s fascinating to examine the conditional character distributions generated by the language model. For example, if you seed the network with “<Tommy Mullaney> “, you’re basically asking it what I’m most likely to say, conditioned on no other context. It turns out my most likely starting character is ‘h’ (~10% of the time, often for ‘hahaha’). It randomly sampled ‘r’ in this case, and you’ll notice that the model then becomes confident that the next character is a vowel. Then after sampling ‘i’ it realizes with nearly 90% confidence that the word has to be ‘right’!
Top 5 predictions for char following "<Tommy Mullaney> ":
'h' 0.101372
'i' 0.0835867
'w' 0.0547253
'a' 0.0547076
't' 0.0521722
Top 5 predictions for char following "<Tommy Mullaney> r":
'e' 0.409155
'i' 0.358729
'o' 0.0960816
'a' 0.0718429
'u' 0.0506499
Top 5 predictions for char following "<Tommy Mullaney> ri":
'g' 0.875222
'd' 0.0680318
't' 0.0138404
'n' 0.00903321
's' 0.00446325
Top 5 predictions for char following "<Tommy Mullaney> rig":
'h' 0.981275
'u' 0.00404702
'g' 0.00294782
'r' 0.00264764
'i' 0.00181549
Top 5 predictions for char following "<Tommy Mullaney> righ":
't' 0.977532
'e' 0.00597925
' ' 0.00362782
'\n' 0.00311822
'i' 0.00264616
<Tommy Mullaney> right
Building an autocomplete
Given these conditional character distributions, you can create a simple ‘autocomplete’ that generates the most probable replies to a given prompt. Instead of randomly sampling from the model, we’ll use a modified beam search to pick out the most likely sequences of characters, subject to a few diversity constraints.
Here are a few examples:
Prompt:
<Tommy Mullaney>
Autocomplete:
1. wow
2. lol
3. true
4. tough
5. hahaha
Prompt:
<Other Person> yo
<Tommy Mullaney>
Autocomplete:
1. ok
2. yo!
3. ...
4. woo
5. good
Prompt:
<Other Person> you around this weekend?
<Tommy Mullaney>
Autocomplete:
1. yup
2. Yup
3. lol
4. yeah
5. nope
Conclusion
While this autocomplete isn’t going to win any awards, it’s a fun proof-of-concept with clear directions for improvement:
- Try using a vocabulary of common words, rather than individual characters, to train the LSTM. This would make the model less susceptible to typos, though at the cost of some expressiveness (typos are a natural part of my personal GChat language model!).
- Try expanding the training dataset to include conversations I had with multiple people.
- Try using a simple n-gram model instead of an LSTM to improve speed/performance.
- Per Google’s Smart Reply paper, cluster responses into common groups based on semantic intent. Then select from this higher-quality ‘response space’ based on the LSTM’s prediction, rather than proposing the raw sequence generated by the LSTM.
- Use these ‘semantic intent’ clusters to eliminate redundant options proposed by the autocomplete.