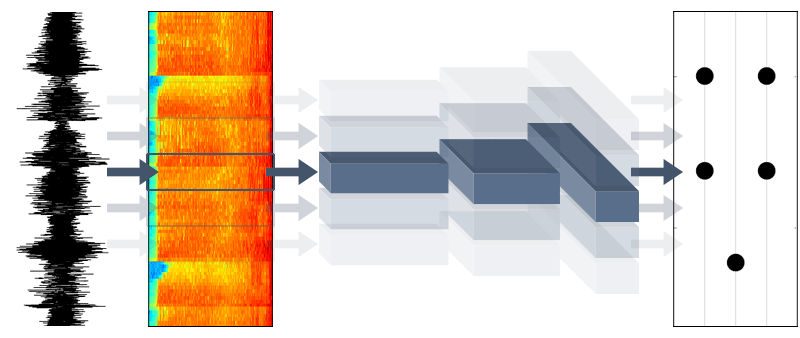
Musical Beat Detection with Convolutional Neural Networks
2016
Rhythm games like Guitar Hero, Rock Band, or Tap Tap Revenge have a common problem: Creating ‘beat tracks’ for users to play along to a song is a time-consuming, labor-intensive task. The problem is similar to music transcription, and today there isn’t an automated system that performs better than humans at this task. Some music games like Rhythmatic automatically generate beat tracks so you can play along to any song you own. However, these automated algorithms aren’t as good as manual transcription, and the logic is usually hard-coded rather than machine-learned. This project uses convolutional and recurrent neural networks to automatically learn a beat detection algorithm from hundreds of human-created beat tracks from the popular iOS music game, Tap Tap Revenge.
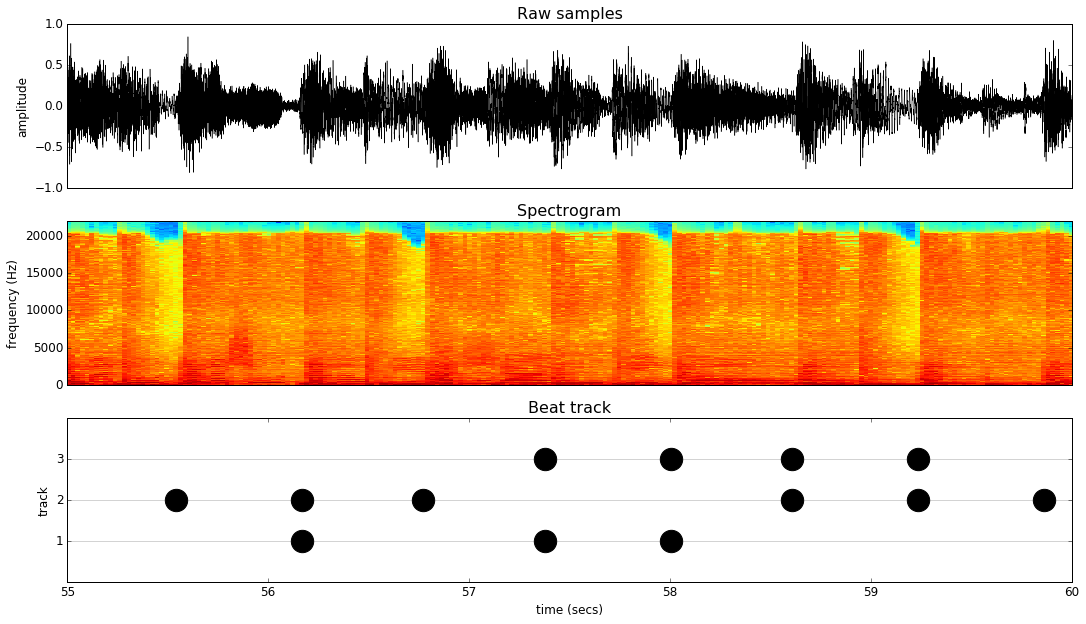
Sneak peak: Here’s a sample beat track generated by my neural network from simply “listening” to a song’s raw audio for the first time:
The problem
Here’s the problem: Given a song’s raw audio samples (usually 44,100 per second!), identify the time and type of all notes in the beat track. For example, here’s a snippet from one song in the training dataset:
Why is this hard?
Identifying notes from either the raw audio samples or the spectrogram is not an easy task – whether you are human or machine. Here are some reasons why it is so difficult:
- Notes are sparse, so you see way more negative cases than positive ones
- You need to identify both the location and type of each note (since there are three tracks, there are seven types of notes; and determining the type of a note requies you to remember and understand the sequence of other notes leading up to it)
- The spectrogram may not contain all information necessary to identify a note, especially since some note choices are subjective
Prior work
Rhythm games like Rhythmatic or AudioSurf use techniques like spectral flux to identify onsets (an onset is the moment when a note starts). The logic is all hard coded.
Recent papers like An End-to-End Neural Network for Polyphonic Piano Music Transcription (2016) and Improved Musical Onset Detection with Convolutional Neural Networks (2014) suggest that neural networks may be able to learn superior algorithms for onset detection.
But while these papers tend to focus on audio recordings of a single instrument (i.e. a piano), we’re going to try full-blown popular songs. And while these papers focus on the objective task of identifying the absolute pitch of a given note, we’re going to tackle the relatively subjective task of identifying “notes” hand-picked by humans for the purposes of fun gameplay.
Approach
We’re going to use two neural networks to generate beat tracks:
- Convolutional neural network (CNN) to identify onsets
- Recurrent neural network (RNN) to classify onsets into particular note types
But before any of that, we need to preprocess the raw data (~480 mp3 files and corresponding MIDI files encoding the beat tracks). In a nutshell, we use a Fast Fourier Transform (FFT) to compute the time-frequency spectrogram for each mp3 file, reduce the frequency dimensionality to 24 “critical bands” following the Bark scale, and then write the values to a CSV file along with the corresponding note (or “no note”) labels for each frame of audio. After all the preprocessing, we have a CSV file for each song where each line corresponds to a single frame of audio. The training dataset spans 100 songs and contains roughly 950,000 lines like this:
[...]
2.862977,2.721762,2.049185,2.315597,2.192046,2.536937,1.839919,0.657465,0.815895,1.539837,-0.605597,-1.038999,0.005878,-1.725802,-1.136734,-1.957330,-2.895736,-3.360324,-2.552099,-2.166407,-3.496811,-4.091577,-3.929893,-8.184432,0,1,0,1,0
2.795352,2.553540,2.583735,2.110682,2.035554,3.166852,2.413250,1.407469,1.437837,1.539810,1.231767,0.216388,-0.165310,-1.847117,-0.491118,-1.554658,-2.079434,-2.493291,-1.465125,-1.929111,-2.900700,-3.007272,-3.090256,-7.732420,0,0,0,0,0
[...]
Now we need to train a CNN to identify onsets from all these numbers. The network architecture looks something like this:
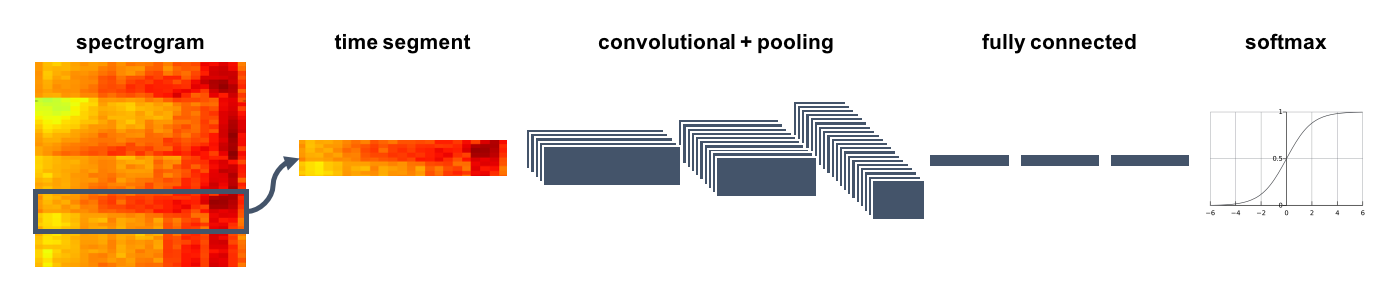
We divide a song’s spectrogram into time segments and feed each segment to the network. Three convolutional layers extract time- and frequency-independent features from the spectrogram, and then three fully connected layers convert this volume into a single feature vector which is fed to a softmax function to produce the final probability of that time segment being an onset. The convolutional layers include max pooling and ReLU units, and the fully connected layers are each followed by a dropout layer to reduce overfitting.
It turns out that learning the note types (i.e. which track a note is on) is a very challenging task. For now, we’re going to take a somewhat simplistic approach of using an RNN to learn a “language model” for rhythm game tracks. In effect, the RNN learns to predict the next note type, given the sequence of note types and times leading up to it. Because we’re not conditioning on the audio features learned by the CNN, we’re not likely to predict the exact right note type for a given note, but we are likely to produce a sequence that resembles normal gameplay.
To help avoid the “vanishing/exploding gradients” problem, I used Long Short Term Memory (LSTM) units to implement the RNN.
Is an RNN overkill for this problem? Probably. I’m sure a simple N-gram model would have similar predictive power with lower computational cost. But RNNs are cool and this project is about seeing what we can do with neural networks.
Putting it all together, the process to generate the beat track for a new song is:
- Compute spectrogram from raw audio samples
- Feed spectrogram to CNN in chunks
- Identify onsets by thresholding and peak-picking from the CNN’s predicted onset probability for each time step
- Sample note types from the RNN, one note at a time
- Combine timestamps + onsets + note types for playback with the original song
Training
These models were implemented using Tensorflow, and trained using the cross-entropy loss function and the ADAM optimizer. Cross-entropy loss is well-suited for classification tasks, and ADAM has been shown to be more effective (often) than other variants of the gradient descent algorithm in related literature.
As with any deep neural network, picking the hyperparameters that define the network shape and size is a bit of a dark art. I don’t have any special insights here other than, be systematic and try a bunch! For these networks, the hyperparameter search space was roughly the following:
CNN
- Number of conv layers
- Size of conv layers
- Number of fully connected layers
- Size of fully connected layers
- Activation threshold for an onset
- Dropout probability
- Learning rate
RNN
- Number of LSTM layers
- Size of LSTM layers
- Number of steps to backpropagate
- Learning rate
After finding the “best” set of hyperparameters, it’s time to optimize the model as much as possible and let it train for a while. On my CPU, 40 epochs of training the CNN over 100 songs took about 6 hours. I tried using GPU spot instances on AWS, but decided after a few runs that the relatively minor improvements in training time were outweighed by the new costs of renting the instances (and dealing with random shutdowns). For the RNN, I trained for 100 epochs (about 5 hours).
Results
The optimal CNN achieved 63% precision and 86% recall on the training set, versus 61% precision and 84% recall on the test set.
Visually, the learned onset detection function for songs looks something like this:


The “onset probability” line is the function – it’s the predicted probability of any timestep being an onset. To actually identify onsets, we use a thresholding function (moving average) and pick peaks. In the first chart you can also see the correct labels from the training set.
If you combine the predicted onsets with the RNN, you can generate “beat tracks” for songs that the models have never seen before. Here are a few examples:
Future
By analyzing examples manually created by humans, these neural networks learned to automatically generate a beat track for any given song. The networks are much faster than a human, and the resulting beat tracks are not only playable but also of surprisingly high quality given the difficulty of the task. This project shows that neural networks can be used to create rhythm games based on any song that a user chooses.
With that said, there’s also a lot of room for improvement. Here are a few areas for further work:
- Combine the CNN and RNN into a single model that can be trained end-to-end. This was my original approach, but I found that training separate models produced better results.
- Add additional preprocessing steps while generating each song’s spectrogram. For example, Mel-frequency cepstral coefficients (MFCC) are commonly used as features in audio recognition tasks.
- Compute multiple spectrograms for each song using different FFT window sizes. This way you could feed the CNN multiple levels of temporal resolution for a given song. This temporal information could help identify onsets, as well as longer-term patterns that occur at different points of the song.